


In-depth guide to fine-tuning LLMs with LoRA and QLoRA
Language Models like GPT-4 have become the de facto standard in the NLP industry for building products and applications. These models are capable of performing a plethora of tasks and can easily adapt to new tasks using Prompt Engineering Techniques. But these models also present a massive challenge around training. Massive models like GPT-4 cost millions of dollars to train, hence we use smaller models in production settings.
But smaller models on the other hand cannot generalize to multiple tasks, and we end up having multiple models for multiple tasks of multiple users. This is where PEFT techniques like LoRA come in, these techniques allow you to train large models much more efficiently compared to fully finetuning them. In this blog, we will walk through LoRA, QLoRA, and other popular techniques that emerged specifically from LoRA.
What is PEFT Finetuning?
PEFT Finetuning is Parameter Efficient Fine Tuning, a set of fine-tuning techniques that allows you to fine-tune and train models much more efficiently than normal training. PEFT techniques usually work by reducing the number of trainable parameters in a neural network. The most famous and in-use PEFT techniques are Prefix Tuning, P-tuning, LoRA, etc. LoRA is perhaps the most used one. LoRA also has many variants like QLoRA and LongLoRA, which have their own applications.
Why use PEFT Finetuning?
There are many reasons to use PEFT techniques, they have become the go-to way to finetune LLMs and other models. But here are some reasons why even enterprises and large businesses like to use these approaches.
Saves Time
As the number of trainable parameters decreases, you have to spend less time on training. But that’s only one part of it. With less trainable parameters, you can train models much faster, and as a result test models much faster too. With more time on your hands, you can spend it on testing different models, different datasets different techniques, and whatnot.
Also, with more time you can train your models for much longer periods of time leading to a much lower loss, along with an increased batch size as PEFT techniques are heavily optimized for memory usage.
Saves Money
This goes without saying but PEFT can save you a ton of money on computing costs. As mentioned, because of heavy memory optimizations, you don’t need to rent instances with high amounts of VRAM, as you can fit bigger batches in smaller VRAM. This saves money on the compute and allows you to train on much bigger datasets leveraging the advantage of fitting in larger batch sizes.
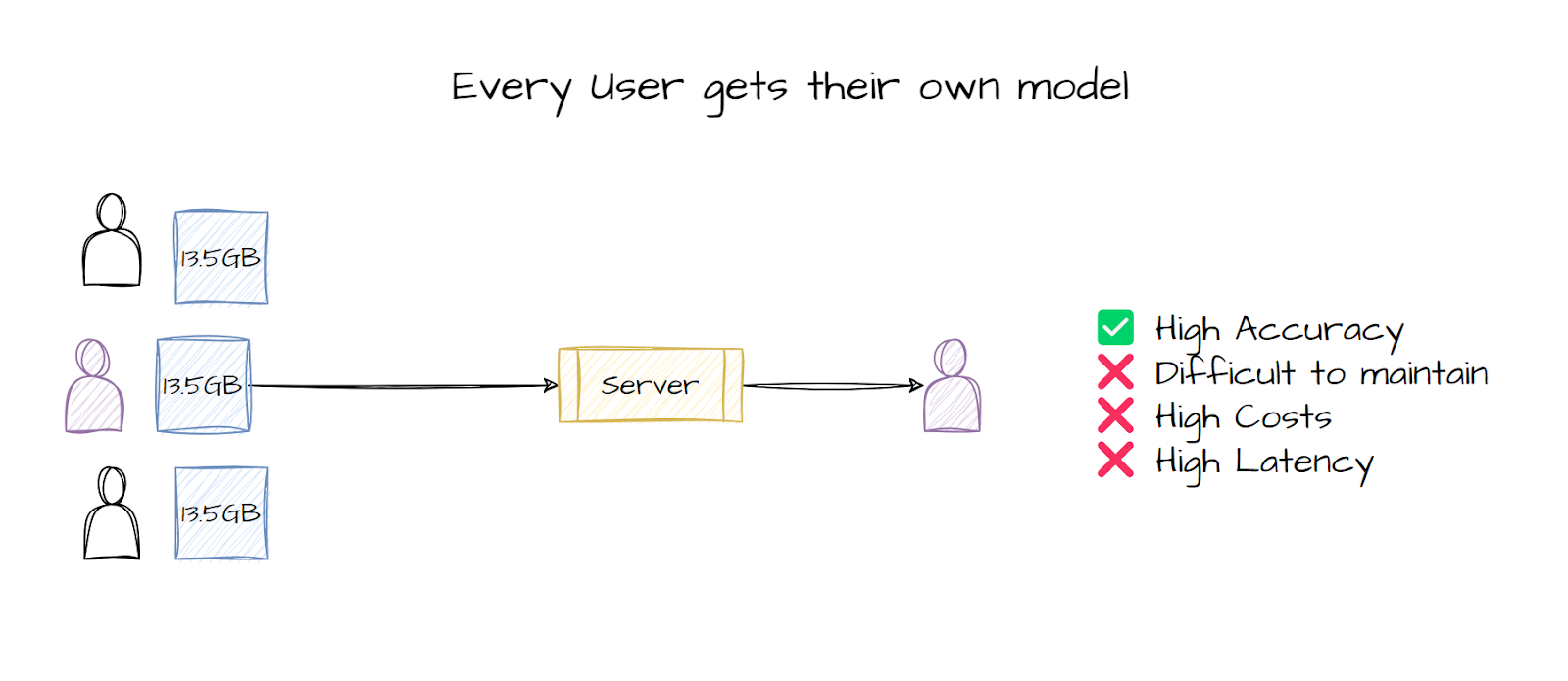
Easily build Multi-Tenancy architecture services
As said, because LLMs have become so large and complicated to serve and handle, it’s almost impossible to train specialized models for users. If you have multiple users, you can either take on the complicated task of finetuning a new model every time a new user comes in, or you can just finetune the same model on the new data for the new user. Both approaches have their own set of issues, if you finetune a new model for every user, it will lead to better accuracy but then you have to handle massive models, load them into memory, store them, process them, etc, it’s an architecture hell and can cause big issues if you make a small mistake. Training the same model for all users is much easier, but then the model accuracy drops significantly.
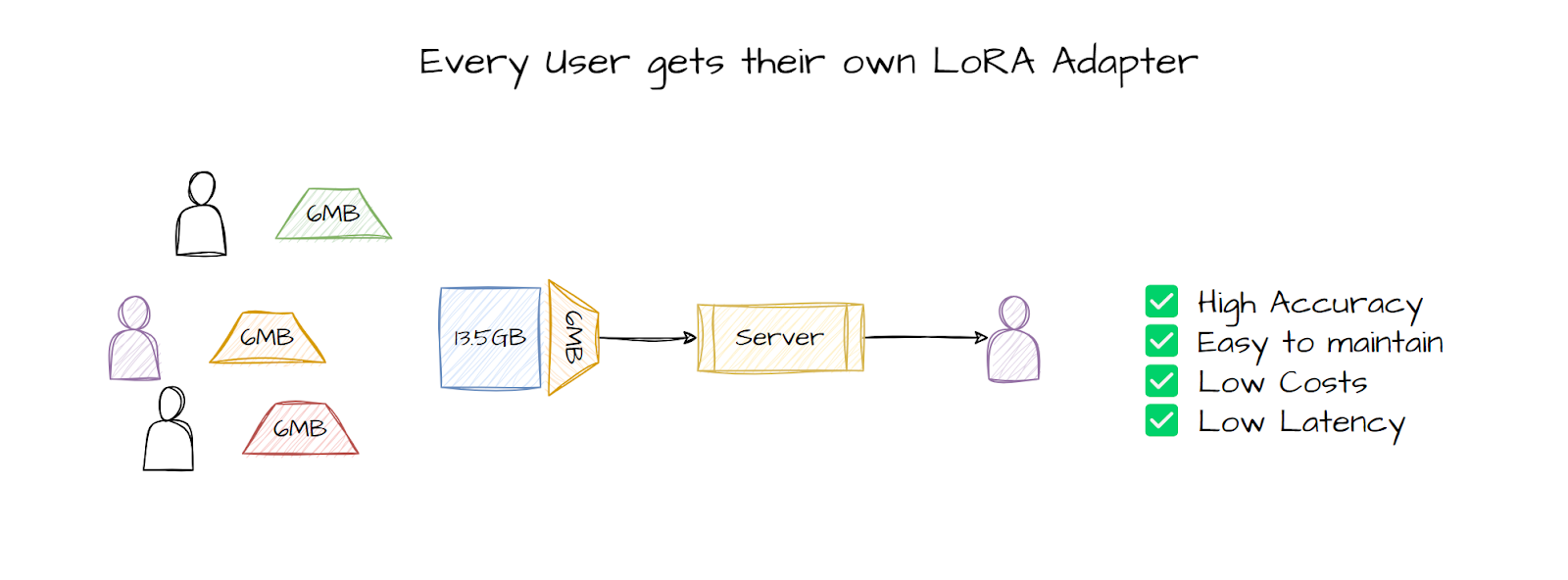
PEFT finetuning on the other hand takes the best of both worlds and lets you build small adapters that you can pair with models and get customized results. These adapters can be finetuned for specific datasets or specific users. These adapters are very small, 6MB-8MB, and you only need to apply these adapters to the large model, which is much faster to do in a production environment.
LoRA Finetuning
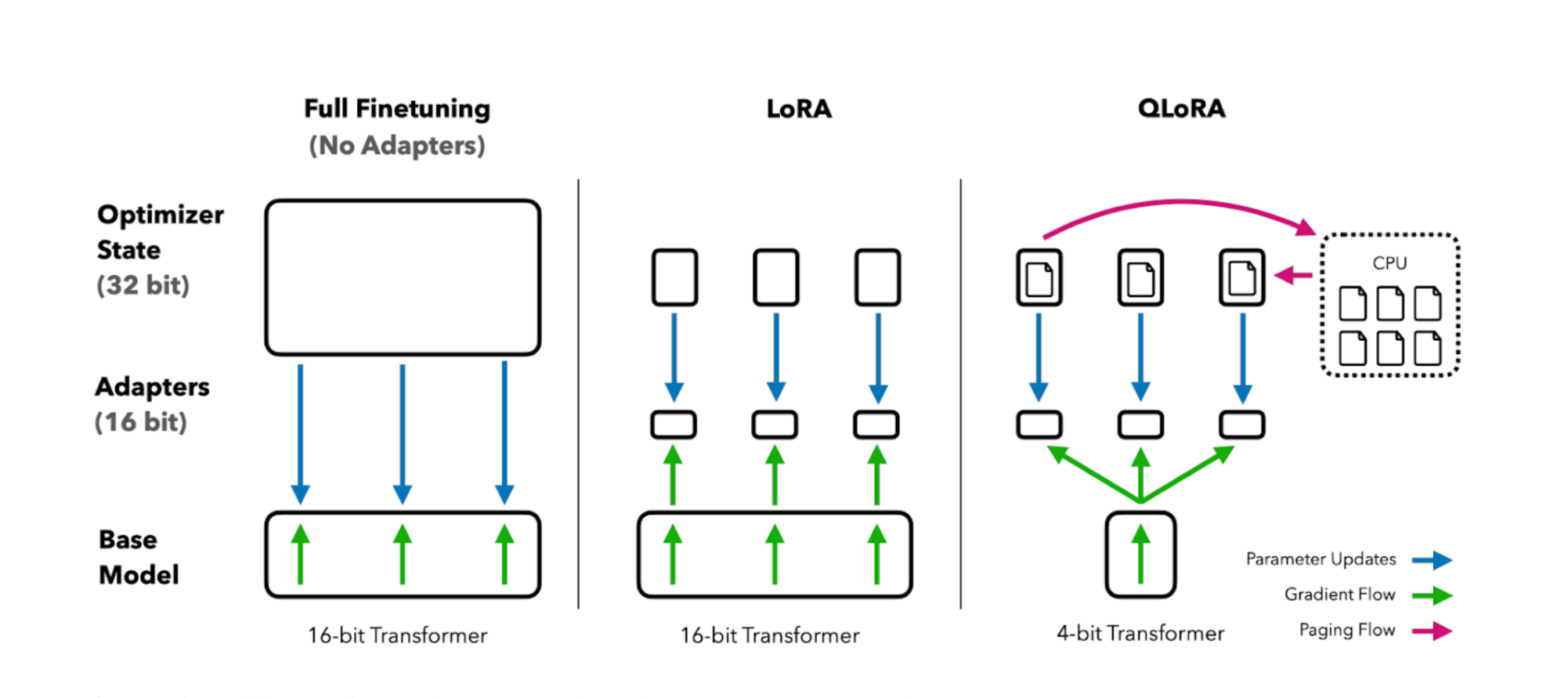
LoRA is the most popular and perhaps the most used PEFT technique, but was released back in 2021 in this paper. LoRA is more of an adapter approach, where it introduces new parameters into the model to train the model through these new parameters. The trick is in how the new params are introduced and merged back into the model, without increasing the total number of params in the model.
How LoRA works?
As mentioned before, LoRA is an adapter-based approach, but new parameters are added only for the training step, they are not introduced as a part of the model. This keeps the model size completely the same and still offers the flexibility of parameter-efficient finetuning. Here’s a more detailed explanation of how it works.
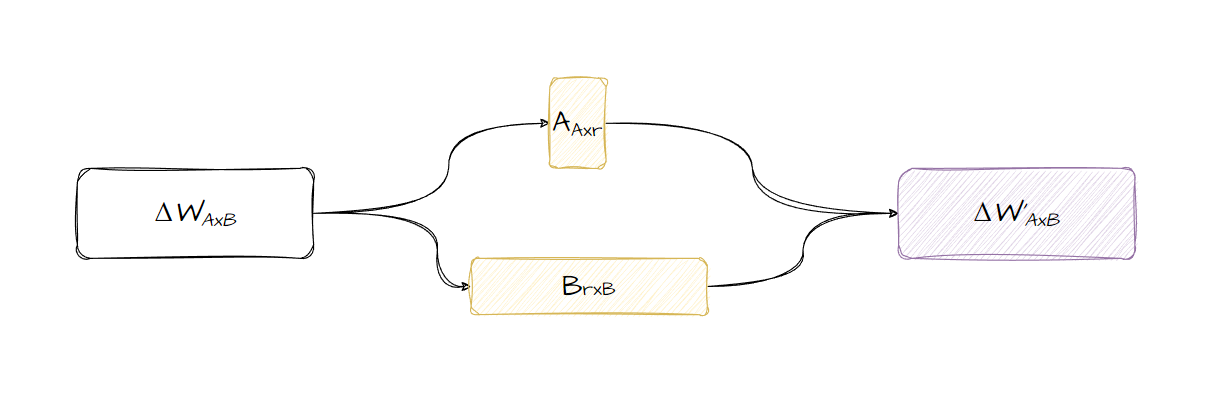
LoRA works by breaking down the weight update matrix into smaller matrices and using them to train the model. Take a look at the diagram below, the ΔWAxB is the weight update matrix, the matrix of learned changes from backpropagation, this is the same size as the number of parameters we need to update to finetune our model. This matrix, or any matrix, can be represented as a set of smaller matrices, presented here as A and B with r as their rank. The r parameter controls the size of the smaller matrices.
These smaller matrices can then be used to train the model using normal backpropagation but updating the parameters in the smaller matrices rather than updating directly in the model. We basically learn the ΔW through the smaller matrices. These smaller matrices can then be multiplied together to get back the original matrix. As these matrices are much smaller, this process uses fewer parameters and as a result much fewer computation resources. This also results in smaller checkpoints as you don’t have to store the whole model, but just the smaller matrices.
LoRA finetuning with HuggingFace
To implement LoRA finetuning with HuggingFace, you need to use the PEFT library to inject the LoRA adapters into the model and use them as the update matrices.
Once this is done, you can train the model as you would normally do. But this time it will take much less time and compute resources as it normally does.
QLoRA Finetuning
QLoRA is a finetuning technique that combines a high-precision computing technique with a low-precision storage method. This helps keep the model size small while still making sure the model is still highly performant and accurate.
How does QLoRA work?
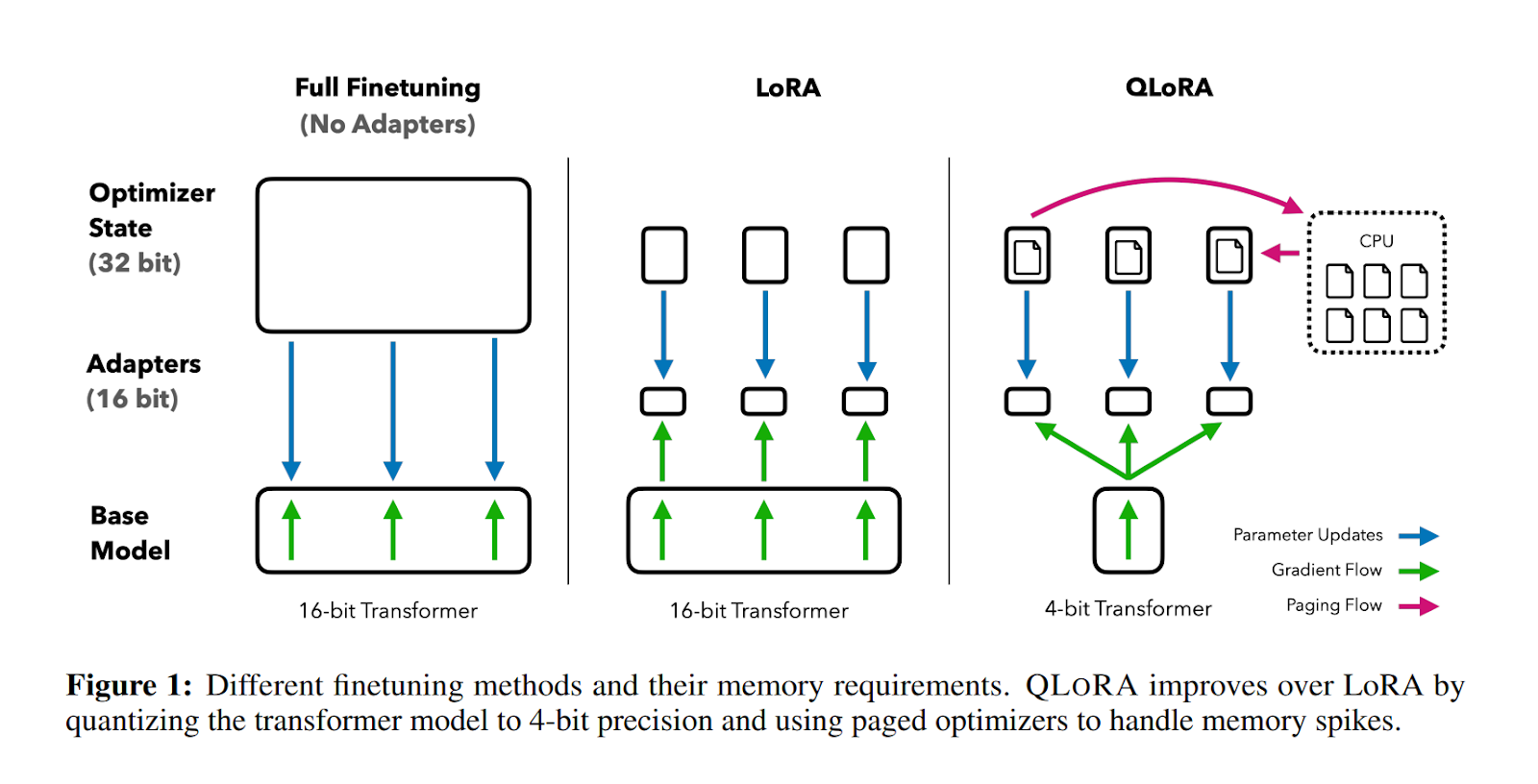
QLoRA works by introducing 3 new concepts that help to reduce memory while keeping the same quality performance. These are 4-bit Normal Float, Double Quantization, and Paged Optimizers. Let’s talk about these 3 very important concepts in detail.
4-Bit Normal Float
4-bit NormalFloat or NF is a new information-theoretically optimal data type built on top of Quantile Quantization techniques. 4-Bit NF works by estimating the 2k + 1 (k is the number of bits) quantiles in a 0 to 1 distribution, then normalizing its values into the [-1, 1] range. Once we have that, we can also normalize our neural network weights into the [-1, 1] range and then quantize into the quantiles we got from step 2.
Here’s an example of what quantile quantization looks like
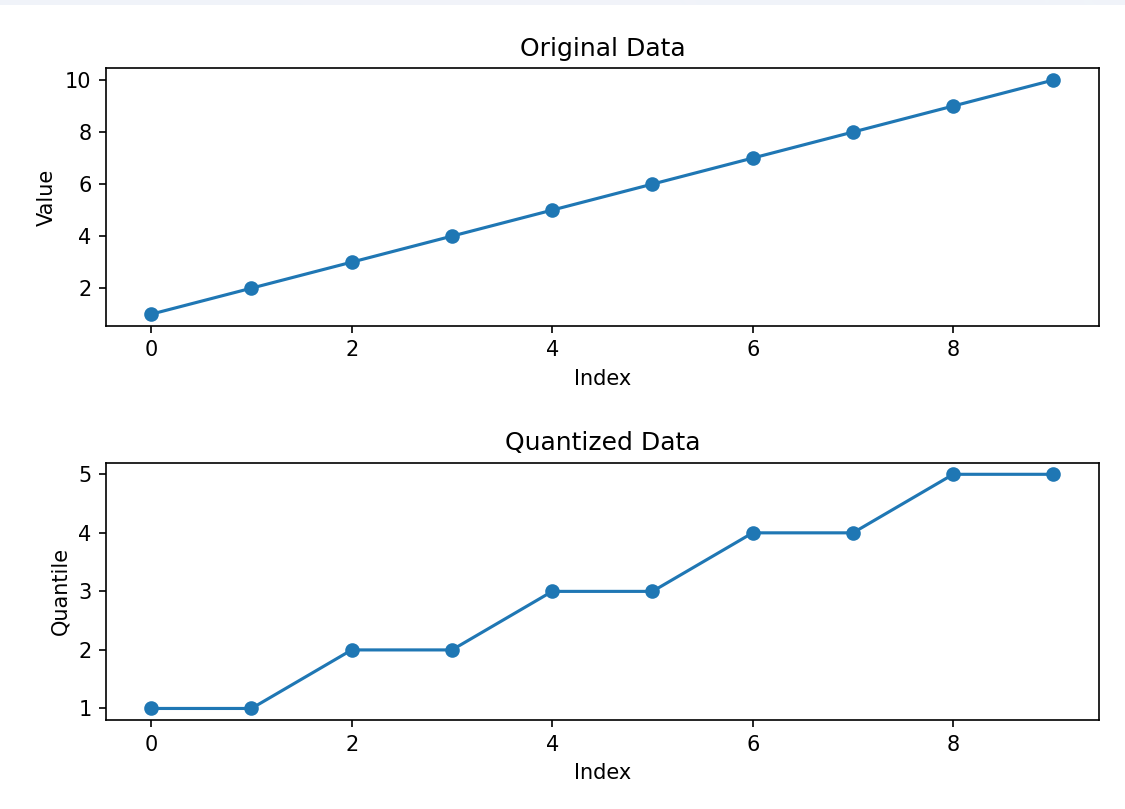
You can see that there are “buckets” or “bins” of data where the data is quantized. Both the numbers 2 and 3 fall into the same quantile, 2. This quantization process allows you to use fewer numbers by “rounding off” to the nearest quantile.
Double Dequantization
Double quantization is the process of quantizing the quantization constants used during the quantization process in the 4-bit NF quantization. This is not important, but can save 0.5 bits per parameter on average, as mentioned in the paper. This helps with the process because QLoRA uses Block-wise k-bit Quantization, meaning instead of quantizing all the weights together, we create multiple chunks or blocks of weights which are then quantized independently.
This block-wise method leads to multiple quantization constants being created, which then once again can be quantized to save additional space. This is okay because the number of quantization constants is low and hence not a lot of computing or storage is required.
Error Reduction with LoRA Tuning
As shown before, quantile quantization creates buckets or bins for a large range of numbers. This process leads to placing multiple different numbers into the same buckets, for example, two numbers 2 and 3 can be converted into 3 during the quantization process. This leads to an error of 1 being introduced during the dequantization of weights.
Here is a graphical representation of these errors on a larger distribution of weights of a neural network.
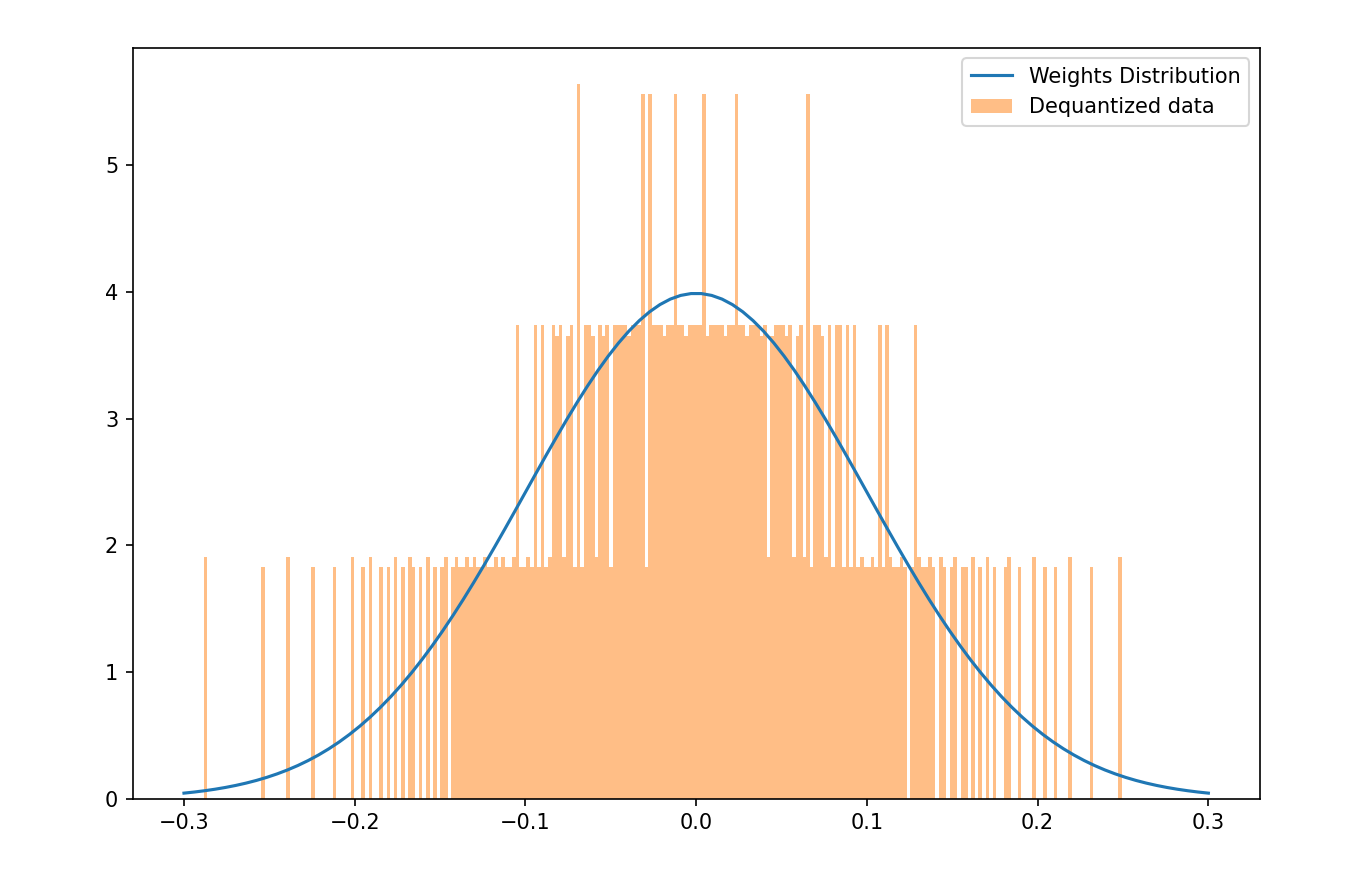
This error is why QLoRA is more of a finetuning mechanism than a standalone quantization strategy. Although it can be used for 4-bit inference. When fine-tuning with QLoRA we use the LoRA tuning mechanism of creating 2 smaller weight update matrices and then using them to update the weights of the neural network. Here, we keep the LoRA matrices in a higher precision format, like brain float 16 or float 16 and during the backpropagation and forward pass the weights of the network are also de-quantized. So the actual training is still happening in higher precision formats, but the storage is still in lower precision. This causes quantization errors to emerge, but the model training itself is able to compensate for these inefficiencies in the quantization process.
Hence, the LoRA training with higher precision helps the model learn about and reduce the quantization errors.
How is QLoRA different from LoRA?
QLoRA and LoRA both are finetuning techniques, but QLoRA uses LoRA as an accessory to fix the errors introduced during the quantization errors. LoRA in itself is more of a standalone finetuning technique.
QLoRA finetuning with HuggingFace
To do QLoRA finetuning with HuggingFace, you need to install both the BitsandBytes library and the PEFT library. The BitsandBytes library takes care of the 4-bit quantization and the whole low-precision storage and high-precision compute part. The PEFT library will be used for the LoRA finetuning part.
And then once again you can move to normal training using the HF trainer. Check out this colab notebook as a guide for QLoRA training.
QLoRA vs Standard Finetuning
In the paper, researchers provide a very detailed comparison between QLoRA, LoRA, and Full Finetuning of a network.
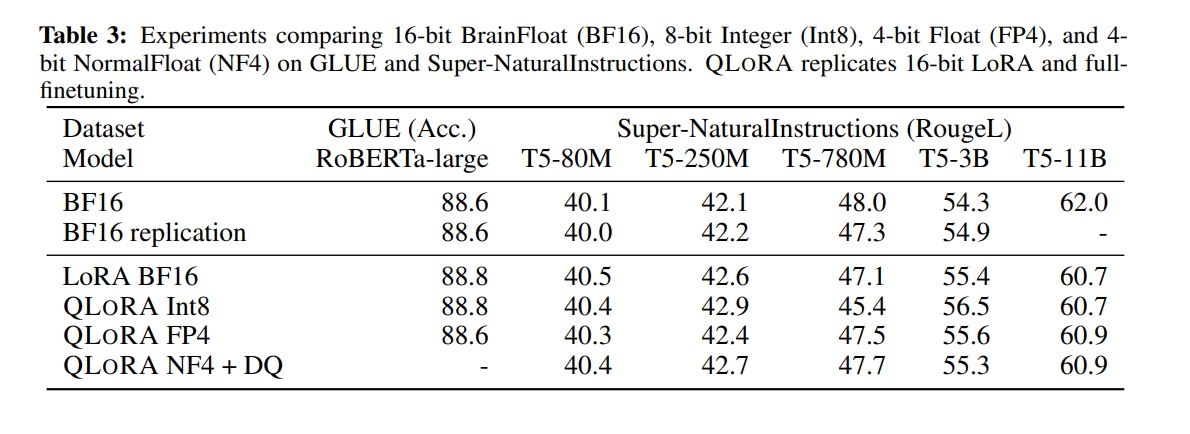
As you can see in the above table, there is no loss of performance whatsoever in the T5 model family upon training with QLoRA and even with Double Quantization, we don’t see any major differences. One significant difference is the number of LoRA adapters required. In the paper, the authors mention that they needed more LoRA adapters for QLoRA finetuning, compared to normal LoRA finetuning. The authors suggest applying the LoRA adapters on all the linear transformer blocks along with the query, key, and value layers.
Even for the much bigger language models, performance remains the same:
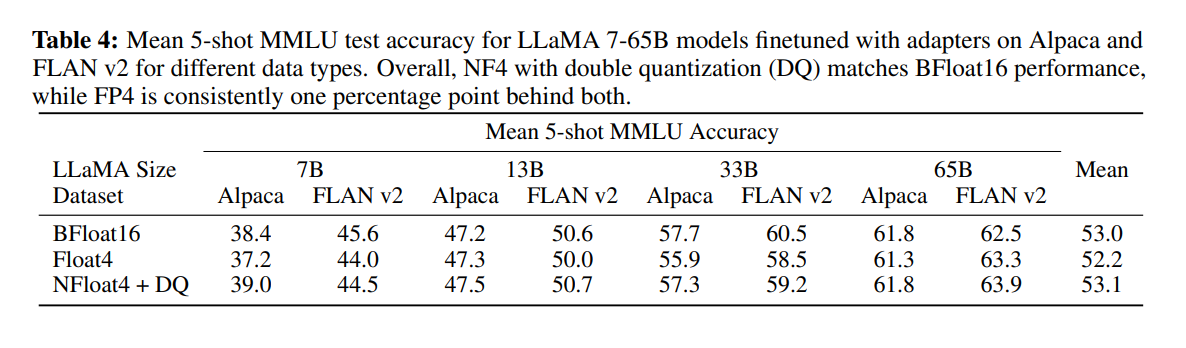
Hence the authors trained a model on top of the base LLaMA models, Guanaco. This is a 33 billion parameter model, trained on the OASST1 dataset. At the time of its release, it became a state-of-the-art model and achieved 99.3% performance relative to ChatGPT. Even though other models have lesser models like Vicuna 13B, and Guanaco33B because of the use of 4-bit precision used less memory than the 13B model.
Other variants of LoRA finetuning
QA LoRA
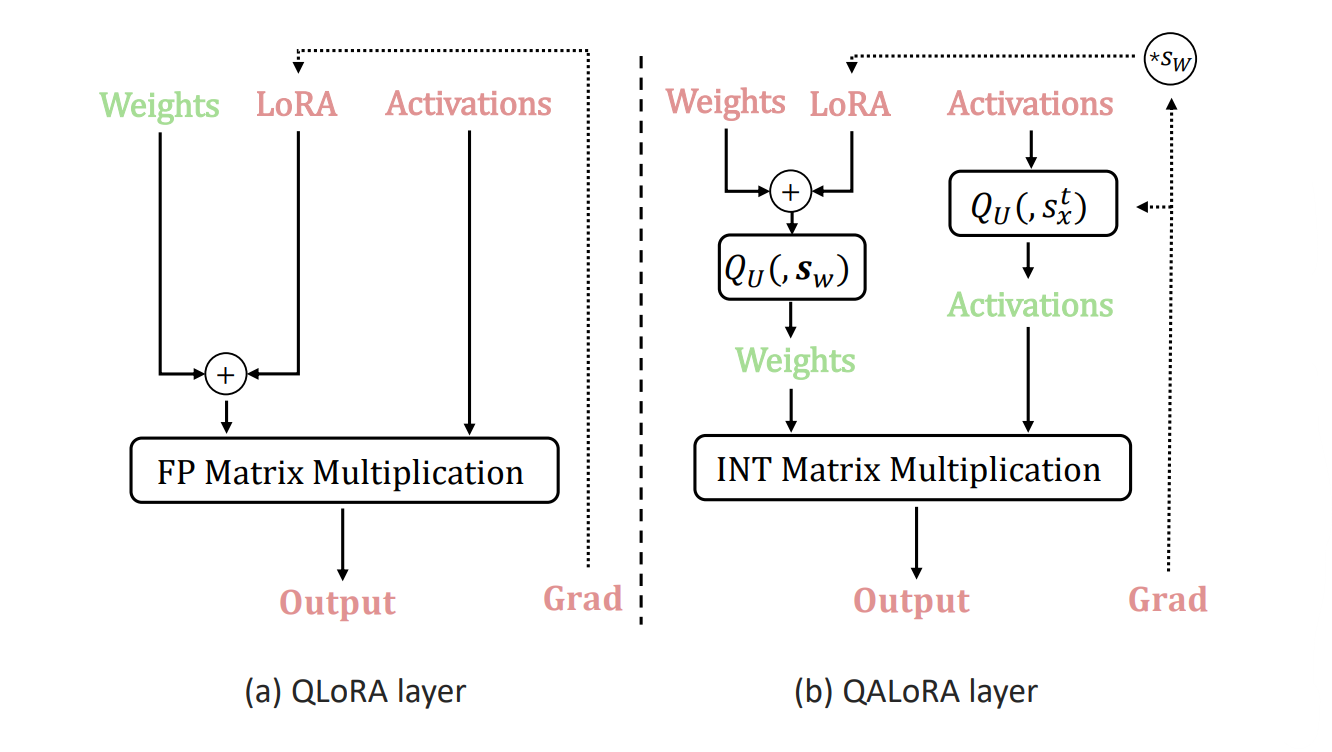
QA LoRA is another fine-tuning technique built on top of QLoRA, introduced in this paper. QALoRA was mainly released for finetuning diffusion models, but can easily be generalized for training any type of models, just like LoRA.
The difference between QLoRA and QALoRA is that QALoRA is quantization aware meaning the weights of the LoRA adapters are also quantized along with the weights of the model during the finetuning process. This helps in more efficient training as there is no need for the conversion step to update the models during the backpropagation process.
LongLoRA
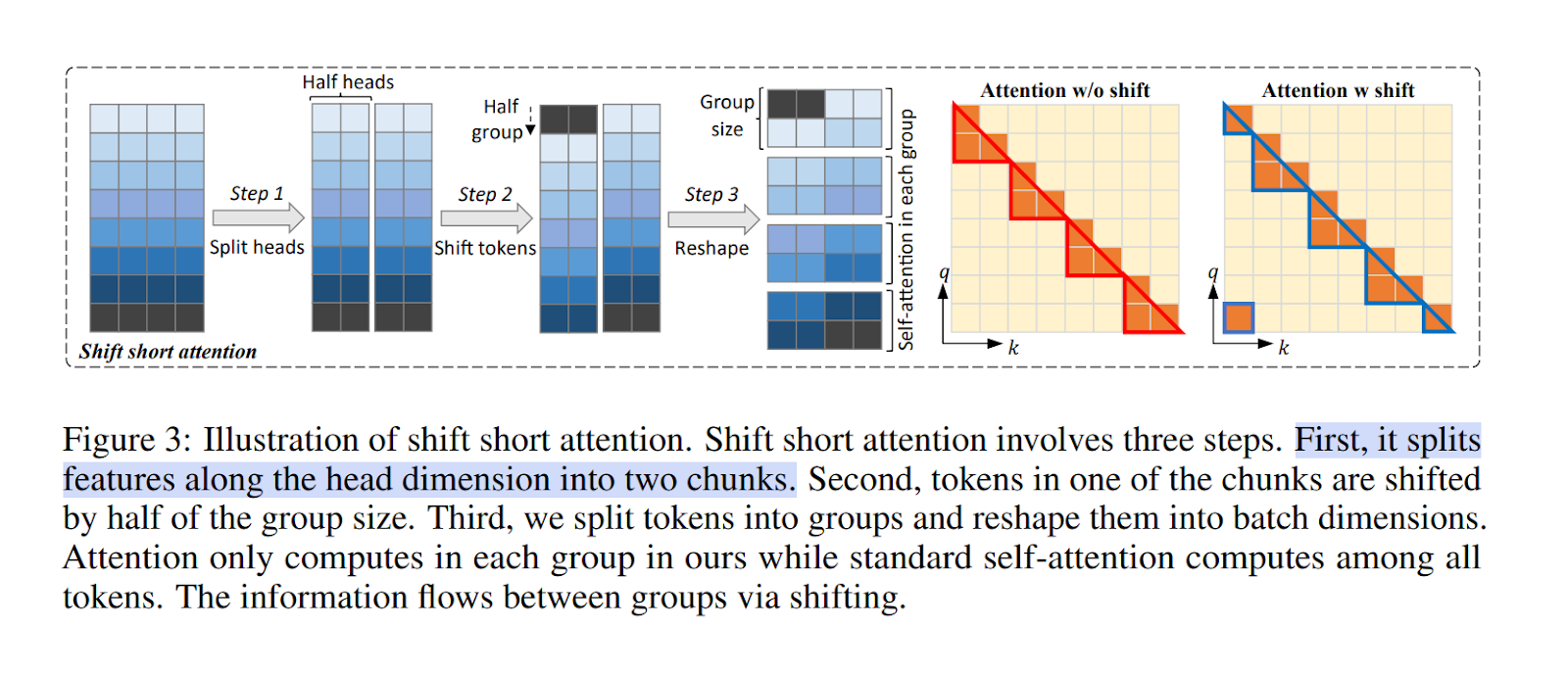
LongLoRA is yet another variation of the LoRA finetuning technique, but this technique is specifically for training longer context models. LongLoRA works by using something called SHIFT SHORT ATTENTION. This method creates chunks or groups of the tokens, in which the attention is calculated independently. This method allows LongLoRA to scale to a much longer context because of the distributed workload.
Along with this, the authors show the need to use the LoRA on the normalization and the embedding layers too for this method to work properly.
AdaLoRA
In traditional LoRA, you fix a rank r for every layer. But different layers contribute differently to model performance.
What AdaLoRA (Adaptive LoRA) does is dynamically allocate the parameter budget i.e. rank to weight matrices based on their importance during training. This avoids the uniform rank allocation of LoRA, which can be suboptimal for layers of varying significance. Important layers (usually the top transformer layers) receive higher ranks, while less critical ones are pruned.
It does so by mimicking the SVD (Singular value decomposition) algorithm for the weight matrices and updating the weights through their singular values:
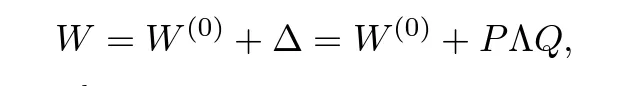
DoRA
DoRA decomposes high-rank LoRA layers into structured single-rank components, allowing for dynamic pruning of parameter budget based on their importance to specific tasks during training, which makes the most of the limited parameter budget. It introduces r′ pairs of single-rank matrices, each acting as a LoRA component. During training, DoRA evaluates the contribution of each component to the overall performance and prunes components with smaller contributions
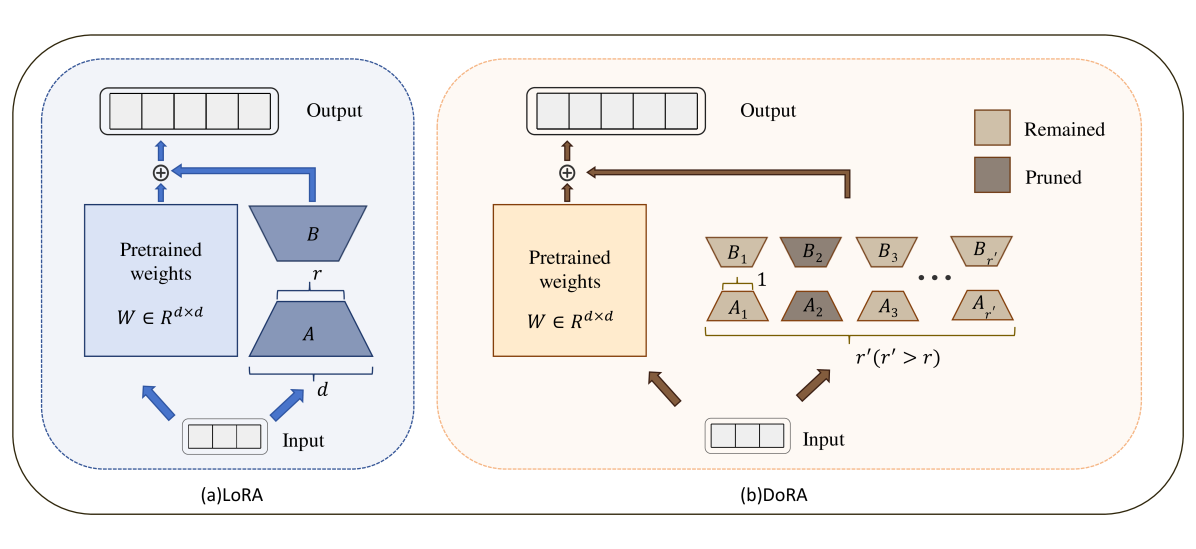
Instead of using a standard LoRA layer, DoRA reinterprets it as:
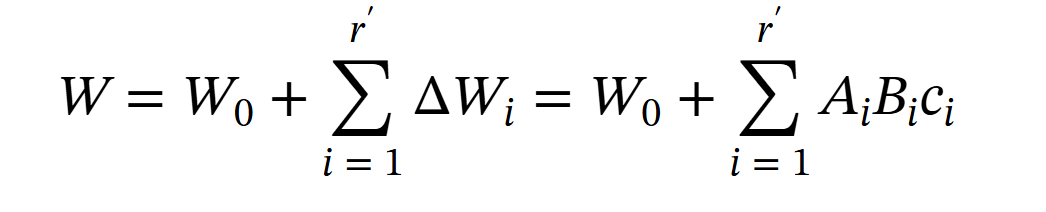
Here r′ represents the number of LoRA components. A LoRA component is a triplet of Ai, Bi, and ci, where Ai and Bi are single-rank matrices, shaped as d×1 and 1×d respectively. ci is a scalar used for pruning the component, it is set to 0 if the component is to be pruned.
DoRA can directly be integrated by the following modifications in the LoRAconfig:
Modern Quantization Strategies (05-2025)
Here are some modern quantization strategies that tend to work really well.
AWQ (Activation-aware Weight Quantization)
AWQ is a post-training quantization (PTQ) technique designed to compress large language models (LLMs) into low-bit formats—specifically 4-bit—without compromising performance. Unlike traditional quantization methods that treat all weights uniformly, AWQ intelligently identifies and preserves a small subset of salient weights that are critical for maintaining model accuracy.
What sets AWQ apart is its approach, rather than analyzing weights directly, it evaluates activation distributions to determine which weight channels are most important. This method eliminates the need for backpropagation or reconstruction, making the process both efficient and highly generalizable across different domains and modalities.
AWQ consistently delivers strong results across various benchmarks, including instruction tuned and multimodal LLMs. For example, it enables efficient 4-bit inference on large models like LLaMA-2 70B, achieving over 3× speedup compared to FP16 implementations—on both desktop and mobile GPUs.
AffineQuant
AffineQuant introduces a novel approach to post-training quantization (PTQ) by leveraging affine transformations to optimize the distributions of both weights and activations. Unlike conventional methods that rely on simple scaling, AffineQuant uses transformation matrices to more accurately align pre- and post-quantization outputs, effectively minimizing quantization errors.
By applying an affine transformation matrix, it adjusts the data distribution to better fit the quantization function, reducing quantization errors. To ensure that the transformation is reversible, AffineQuant employs a gradual mask optimization method, initially focusing on diagonal elements and gradually extending to other elements (ensuring invertability). This approach aligns with the Levy-Desplanques theorem, guaranteeing the invertibility of the transformation.
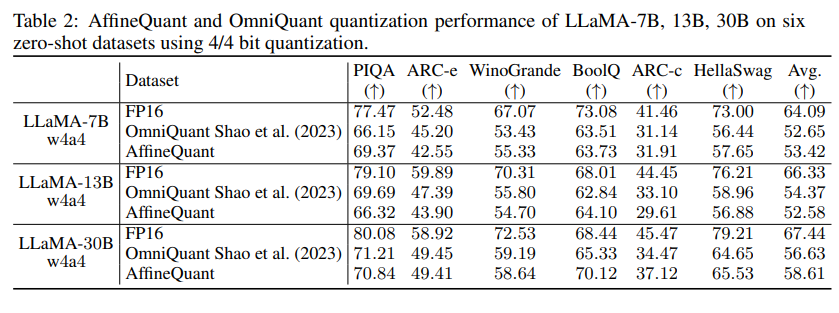
AffineQuant sets new standards for PTQ in LLMs. For instance, it achieves a C4 perplexity of 15.76 on the LLaMA2-7B model using W4A4 quantization—surpassing previous methods like OmniQuant. On zero-shot tasks, it reaches an impressive average accuracy of 58.61% with 4/4-bit quantization on LLaMA-30B, marking a notable leap in performance over existing techniques.
Dynamic 4-bit Quantization
Dynamic 4-Bit Quantization, as implemented by Unsloth, offers a flexible approach to quantizing LLMs. Unlike static quantization methods, dynamic quantization adjusts to the model's precision levels on the fly during runtime, ensuring better performance and resource usage.
Built on top of BitsandBytes (BnB) 4-bit quantization, this dynamic strategy offers visible accuracy improvements while using <10% more VRAM compared to standard BnB 4-bit implementations
Unsloth's dynamic 4-bit quantization has shown to provide accurate and reliable results, often outperforming standard 4-bit quantization methods. For instance, while standard quantization may degrade model performance, Unsloth's approach maintains high accuracy, reducing memory usage significantly. For example, compressing Llama 3.2 Vision (11B) from 20GB to just 6.5GB while maintaining its high accuracy.
How finetuning improves model performance for your business
If you are considering finetuning a model for your business, you are probably correct. But data becomes an important part of the process, take a look at our synthetic data generation guide. However, there are many ways fine-tuned models can improve the performance of your business by providing customization. Finetuning the models helps you customize the model to your specific needs and knowledge. You can use an RAG pipeline to customize the model, but sometimes the knowledge is so vast that embedding and similarity searches are not enough, that’s where customization via finetuning comes in.
If you need finetuned models for your business, reach out, don’t be shy. We have a ton of experience in finetuning all kinds of models, from small T5 models to massive models like Falcon180B. We have seen it all.